در بخش دوم از مرور کتاب
«آمار کاربردی در پژوهشهای پزشکی» تالیف
پروفسور آلتمن، میخواهم نگاهی عمیقتر به فصول این کتاب بیندازم و از این نگاه به برخی ویژگیهای مهم و مثبت این کتاب، اشاره نمایم:
در
فصل اول این کتاب، مولف با یک نگاه کل به جزء (یا همان رویکردی که گاهی به رویکرد درختی مشهور است که منظور از درخت، تشبیه نگاه از تنه درخت به ساقه های اصلی یا ضخیم، سپس به ساقه های باریکتر و در نهایت، برگها میباشد)، ابتدا در خصوص علم آمار و گستره موضوعی آن به اختصار مطالبی را بیان داشته و سپس به گستره موضوعی آمار در پزشکی (آمار پزشکی یا همان آمار زیستی) میپردازد.
جالب است که در همین نگاه مقدماتی، به وضوح میتوانیم به تفاوت بارز این کتاب با سایر کتب آماری یا حتی سایر کتب آمار کاربردی، پی ببریم. چون در همین نگاه مقدماتی، بیشتر سطور و محتوای این بخش، پر است از مثالهای متعدد واقعی که قطعاً خواننده را به ادامه خواندن این کتاب علاقمند مینماید. در انتهای این فصل که بیشتر جنبه مقدماتی دارد، نگاه بسیار خلاصه ای به کل محتوای کتاب داشته و هدفش را از تالیف این کتاب که درک ساده و بدون دشواری از آمار میداند، به خواننده منتقل مینماید.
در
فصل دوم این کتاب،
انواع داده ها یا متغیرها در آمار کاربردی توضیح داده شده و سپس مختصری به انواع شاخصهای پرکاربرد در آمار زیستی میپردازد. سپس به برخی سنجشها یا اندازه گیریها در متغیرهای مختلف پرداخته و ضمن بیان برخی از این انواع سنجش مهم مانند مقیاس بصری آنالوگ یا Visual Analoge Scale یا VAS به ملاحظات کاربردی این نوع سنجشها اشاره داشته و در انتها برخی موضوعات عملی جمع آوری داده ها مانند پدیده سانسور شدن داده ها و همچنین پراکندگی یا تغییرات در اندازه گیری یا همان موضوع پایایی را مورد توجه قرار میدهد.


در
فصل سوم این کتاب با عنوان
«توصیف داده ها»، ابتدا به تبیین شاخصهای مرکزی و پراکندگی و انواع این شاخصها (یعنی میانگین، میانه، نما و دامنه، دامنه بین چارکی، واریانس و انحراف معیار) میپردازد. رویکرد پروفسور آلتمن
در تشریح مبانی نظری و کاربردهای عملی این شاخصها که در کمتر کتاب آماری مورد استفاده قرار گرفته، بدین صورت است که به تمامی این شاخصها، از دیدگاه نموداری یا دیدگاه بصری، نگاه کرده و این موضوع درک این شاخصها را برای خواننده، بسیار ساده مینماید.
در همین فصل و در ادامه این مطالب، به بیان توزیع ها (البته به بصورت نظری، بلکه کاملاً عملی و کاربردی) و برخی ویژگیهای ملموس در توزیعهای متغیرهای کمی، مانند عدم تقارن یا چولگی میپردازد.
با مثالهای عملی متعددی از متغیرهای مختلف پرکاربرد در آمار زیستی، به راهکار تغییر متغیر یا ترانسفورماسیون پرداخته و شاید تنها کتاب یا منبع معتبری باشد که خوانند را در زمینه نوع تغییر متغیر ریاضی (ترانسفورماسیون) برای متغیرهای مهم و پرکاربرد پزشکی (مانند متغیرهای سرولوژی یا تیتر آنتی بادیها و ...)، راهنمایی میکند.
در انتهای این فصل، به دو ابزار دیگر مورد استفاده در آمار توصیفی، یعنی جداول و نمودارها اشاره داشته و البته بدیهی است که دیگر نیازی به توضیخات اضافه در مورد این دو ابزار آمار توصیفی نمیبیند، چرا که همانطور که پیشتر عرض نمودم، رویکرد کاربردی مورد استفاده ایشان در بیان شاخصهای مرکزی و پراکندگی، استفاده از نمودارهای مختلف است که خودبخود موضوع نمودارها را برای خواننده، سهل و کاربردی نموده است.
در
فصل چهارم کتاب آمار کاربردی در پژوهشهای پزشکی، با عنوان
توزیعهای نظری یا تئورتیکال، ابتدا به بیان مطالب کاربردی در احتمالات پرداخته و قوانین ساده احتمال (قوانین جمع و ضرب) را با مثالهای ساده ای بیان میکند. پس از آن به تعریف کاربردی از جامعه و نمونه میپردازد.
پس از این مطالب مقدماتی، توزیعهای مهم آماری را ابتدا از توزیع نرمال آغاز میکند. در بیان مبانی نظری توزیع نرمال، مثالهای متعدد این کتاب، درک این مطالب را برای خواننده بسیار ساده میکند.
یک نکته جالب توجه و متفاوت در این کتاب، این است که مانند بسیاری از کتب آماری دسته بندی توزیعهای آماری مهم را بر حسب توزیعهای پیوسته و گسسته، بیان نداشته و حتی در طبقه بندی نیز قائل به کاربرد توزیعها میباشد.
ضمناً بدنبال بیان توزیع نرمال و ذکر مثالهای متعدد، توزیع log-Normal Distribution را نیز مورد بحث قرار داده و به کاربردهای آن نیز اشاره مینماید.
پس از تشریح دو
توزیع نرمال و
لگاریتم-نرمال،
توزیع دو جمله ای را مورد بحث و ارزیابی قرار داده و در ادامه آن نیز
توزیع پواسون را با مثالهای متعدد، تشریح میکند. یک موضوع جالب توجه هم این است که در این دو توزیع آماری گسسته، اگر خواننده یا فراگیری، قصد درک موضوع مهم و کاربردی،
تقریب توزیع نرمال در دو توزیع پرکاربرد دو جمله ای و پواسون را دارد، میتواند با مراجعه به این فصل و مطالب و مثالهای مورد استفاده در این بخش، بسهولت و کاملاً کاربردی، این مفهوم مهم و پرکاربرد را درک نماید.
در
فصل پنجم این کتاب، همانطور که در بخش اول این مقاله آمده بود، مبحث
متدولوژی یا روش شناسی پژوهشهای کاربردی در علوم پزشکی، تشریح میگردد. این فصل با اینکه دارای یک محتوای
40 صفحه ای است، اما بخوبی میتواند برای مرور روش شناسی پژوهشهای پراستفاده در علوم زیستی پزشکی، منبع مطالعاتی بسیار مفیدی باشد. در این فصل پس از دسته بندی رایج انواع مطالعات به مطالعات مشاهده ای و مداخله ای، طراحیهای رایج این دو دسته را مورد توجه قرار میدهد.
جالب این است که در هر یک از طراحیهای رایج، سوگراییها یا Bias های معمول آن دسته از مطالعات را با ذکر مثالهای متعدد، تشریح مینماید. ناگفته نماند که در این فصل، بیشترین حجم مطالب به طراحی کارآزماییهای بالینی و سوگراییها یا ملاحظات مهم مرتبط با طراحی آنها، اختصاص دارد.
همچنین در این دسته از مطالعات، روشها یا استراتژیهای مختلف تخصیص تصادفی یا Random Allocation از جمله روش تخصیص تصادفی بلوکی را بخوبی و با مثالهای کاربردی، تشریح مینماید.
در پایان این فصل، نحوه انتخاب بهترین یا مناسبترین طراحی مطالعات پژوهشی در شرایط مختلف را، توضیح داده است.
فصل ششم این کتاب، تحت عنوان
«استفاده از یک رایانه»، با توجه به دوره زمانی نگارش کتاب (اوایل دهه 1990 میلادی) و تغییر و تحولات بسیار جدی در این زمینه، طی دو تا سه دهه اخیر، عملاً کاربرد مطالب بیان شده در این فصل،
بسیار محدود میباشد.
 فصل هفتم
فصل هفتم این کتاب، تحت عنوان
«آماده سازی برای تحلیل داده ها» نیز یک فصل کاملاً متمایز در مقایسه با سایر کتب آماری است. برای اینکه بخوبی این تمایز را بشناسید، باید اشاره نمایم که این فصل محتوی سه موضوع مهم و کاربردی
چک داده ها، پالایش داده ها و غربالگری داده ها یا همان Data Checking, Data Cleaning & Data Screening است. شاید بجرات بتوان ادعا نمود که اصول و مبانی عملی یا کاربردی موجود در این فصل را نمیتوان در هیچ منبع دیگری (اعم از مقاله مروری یا متدولوژیک، کتاب و یا ...) پیدا نمود.
خوب به یاد دارم که وقتی در سالهای میانی دوره دکترای تخصصی بودم (سالهای 1382 یا 2003 میلادی)، برای یک پروژه چند مرکزی و بزرگ کشوری که دارای حجم نمونه ای بیش از 6000 نفر بود، بعنوان تحلیلگر داده های مطالعه مزبور انتخاب شدم. بدیهی است که در اواسط فرایند اجرایی مطالعه (تقریباً در اکثر مراکز، عملیات جمع آوری داده ها، به اتمام رسیده بود)، این جایگاه به بنده داده شده بود و بعنوان اولین اقدام ظرف 2 هفته انتظار داشتند که گزارش اولیه ای از کیفیت اجرای مطالعه از
تا آن زمان، ارائه نمایم. منطقی بود که اولین گزارش را نه به یافته های این مطالعه بزرگ، بلکه به کیفیت فاز جمع آوری داده ها، مبتنی بر ارزیابی کیفیت داده های جمع آوری شده، اختصاص دهم. نکته جالب توجه این موضوع آن بود که علی رغم اینکه کلیاتی از موضوع پاکسازی و چک داده ها میدانستم، اما دوست داشتم که این کار یا گزارش، حتماً بر اساس شواهد قوی از فرایند پاکسازی داده ها استفاده نماید. تمایل داشتم که برخورد با داده های گمشده یا Missing data و همچنین برخورد با داده های پرت یا Outlier و ...، کاملاً بر اساس شواهد متقن مورد اشاره در متون باشد و نه اینکه بعنوان یک روش سلیقه ای بدان نگریسته شود. اما هر چه که خود موضوع، بنظر ساده و ابتدایی میآمد، اما در هیچ منبع یا کتابی قادر به یافتن مطالب مربوطه نبودم. شاید بیش از 15 کتاب بسیار معروف آماری و آمار کاربردی را به دقت زیرورو کردم، اما هیچ فایده ای نداشت، تا اینکه یک روز بصورت کاملاً تصادفی سراغ کتاب پروفسور آلتمن رفتم و متوجه شدم در این کتاب به ظاهر مقدماتی و ساده، آنچه من بدنبالش بودم را به بهترین فرمت موجود، دارد و انگار این فصل برای کاربردی که من میخواستم نوشته شده بود!!!!
جالب این است که حتی با گذشت سالها از آن دوران و انتشار کتب متعدد آمار کاربردی، هنوز هم به احتمال خیلی قوی، این کتاب بطور انحصاری تنها منبع علمی موضوع یاد شده میباشد. حال میخواهم از همه شما عزیزان و علاقمندان خواهش کنم که قدر این گنجینه ارزشمند را بدانید و از آن استفاده نمایید.
بعنوان آخرین و مهمترین نکته در مورد مطالب فصل هفتم، باید عرض کنم که علاوه بر اهمیت بعد نظری یا مبنایی مطالب این فصل در آمار کاربردی، از منظر عملی و کاربردی، هر پژوهشگری که حداقل یک پژوهش یا مطالعه با حداقل یکی از سه ویژگی بزرگی حجم نمونه، تعداد بالای متغیرهای مطالعه و یا تنوع متغیرهای مطالعه داشته باشد، میتواند از مطالب این فصل، بصورت کاملاً کاربردی برای چک داده ها، پاکسازی داده ها و غربالگری داده ها، استفاده نمایید.
 فصل هشتم
فصل هشتم کتاب،
«اصول تجزیه و تحلیل آماری»، سرآغاز مبحث آمار تحلیلی در این کتاب بوده و بدیهی است که دارای دو مبحث نظری «برآورد» و «آزمون فرضیه»، البته با فرمت یا شیوه بسیار کاربردی و مفید است. در این فصل، منطق آزمونهای آماری مهم و پرکاربرد، مانند آزمون T یا کای دو و ...، بخوبی و با مثالهای متعدد توضیح داده شده است. همچنین تفاوت دو دسته آزمونهای پارامتریک و ناپارامتری نیز در همین فصل مورد توجه قرار گرفته است.
در
فصل نهم این کتاب، که عنوان آن
«مقایسه گروهها: داده های کمّی» است، مطالب به دو بخش مقایسه داده های کمی در دو گروه و بیش از دو گروه (سه گروه و بیشتر)، طبقه بندی شده است. ابتدا به بیان آزمونهای آماری مختص دو گروه اشاره شده و سپس به مبحث مقایسه در سه گروه و بالاتر، پرداخته شده است:
توزیع t، آزمونهای t تک گروهی، آزمون t دو گروه مستقل و آزمون t در دو گروه وابسته یا همان آزمون معروف t زوج یا paired t test، تشریح شده و همراه با مثالهای متعددی
برای خوانندگان تبیین شده است. در ادامه همین فصل، آزمونهای ناپارامتری معادل تی مستقل و تی زوج، یعنی آزمونهای U مان ویتنی و ویلکاکسون نیز توضیح داده شده و به کاربردهای آنها نیز اشاره گردیده است.
در بخش مقایسه در بیش از دو گروه ابتدا منطق آزمون تحلیل واریانس یا ANOVA، البته Oneway ANOVA که به رابطه بین یک متغیر دسته بندی شده دارای بیش از دو سطح (یا بیش از دو لایه) با یک متغیر وابسته کمّی میپردازد اشاره گردیده و سپس به آزمون ناپارامتری معاول آن، یعنی آزمون کروسکال والیس و کاربرد آن پرداخته شده است.
در
فصل دهم با عنوان
«مقایسه گروهها: داده های دسته بندی شده»، ابتدا به آزمون آماری مقایسه دو فراوانی یا دو سهم (proportion) اشاره شده و به دنبال آن، منطق آزمون آماری کای اسکویر (کای دو) مورد بحث قرار گرفته و سپس به مبانی نظری این آزمون در مقایسه فراوانیهای متعدد در قالب یک جدول توافقی یا contingency table که گاهی نیز به جدول r*c نیز معروف است، پرداخته شد. در ادامه این فصل، وضعیتهای خاص این گروه از آزمونها، یعنی آزمون دقیق فیشر، آزمون مک نمار (مقایسه دو فراوانی وابسته یا زوج که در طراحیهای همسان سازی شده یا طراحیهای قبل و بعد مورد استفاده قرار میگیرد) و همچنین آزمون کای دو برای تحلیل روند (یه به اختصار Chi square for trend) اشاره گردیدو با مثالهای متعددی، جایگاه کاربردی این خانواده از آزمونهای آماری که در برخی منابع به Categorical Statistical Tests معروف شده اند، تشریح نموده است.
مولف، در ادامه این فصل و با توجه به فیلد موضوعی این کتاب که آمار زیستی است، ضمن معرفی ارتباط طراحی مطالعات مشاهده ای پرکاربرد در این علوم، یعنی مطالعات مورد شاهدی یا کوهورت با شاخصهای اندازه اثر روتین در این طراحیها، یعنی شاخصهای خانواده خطر نسبی یا Relative Risk (نسبت برتری یا odds ratio، نسبت خطر یا risk ratio)، شیوه محاسبه این شاخصها و همچنین خطا معیاریا standard error آنها، بمنظور برآورد فاصله اطمینان 95 درصد این شاخصها، را بطور کامل و با مثالهای متعدد، تشریح نمود.

 فصل یازدهم
فصل یازدهم، یکی از فصول مورد علاقه پروفسور آلتمن است. اگر بیاد داشته باشید، در قسمت اول این مقاله که به زندگینامه مختصر ایشان اشاره داشتم، در طول سالهای دهه 1980 میلادی و سالهای آغازین دهه 1990 میلادی (سالهای نگارش این کتاب)، مصادف با سالهایی است که ایشان به محدودیت مهم آنالیز همبستگی و همچنین سوء برداشتهای شاخص ضریب همبستگی در پژوهشهای علوم پزشکی تمرکز نموده بود و در همین دوره است که مقاله معروف ایشان در ژورنال معتبر لنست، منتشر گردید و غوغای زیادی در بین پژوهشگران و متخصصین ایجاد نمود. فلذا موضوع این فصل با عنوان «ارتباط بین دو متغیر کمّی» با توضیح و تشریح مبانی نظری تحلیل همبستگی آغاز گردیده و با مثالهای متعددی به محدودیتهای این شاخص میپردازد. پس از تبیین انواع ضریب همبستگی (انواع پارامتریک یا پیرسون و ناپارامتری یا اسپیرمن) و همچنین Partial Correlation Coefficient به تبیین تحلیل رگرسیون خطی مپردازد. در ادامه مولف به تبیین بسط روشهای رگرسیونی، مانند رگرسیونهای غیرخطی و کاربرد آنها میپردازد.
 فصل دوازدهم
فصل دوازدهم با عنوان
«روابط بین چندین متغیر»، ابتدا به بیان توسعه دو روش رگرسیون و آنالیز واریانس برای پاسخ به این شرایط، میپردازد. آنالیز واریانس دو طرفه و همچنین وارد نمودن سنجشهای تکراری در این آزمون (یعنی همان Repeated measures ANOVA) را با مثالهای متعددی تشریح میکند. سپس به بیان کاربرد و تشریح تحلیل رگرسیون خطی چندگانه یا چند متغیره میپردازد. مدلسازی رگرسیونی را نیز مورد توجه قرار داده و شیوه های دستیابی به مدل رگرسیونی نهایی یا final model را نیز مورد توجه قرار میدهد. مدلهای اتوماتیک (مانند backward elimination یا forward selection) نیز مورد توجه قرار گرفته است. در ادامه روش رگرسیون خطی چندگانه، روشهای رگرسیون لجستیک و discriminant analysis نیز توضیح داده شده است.

در
فصل سیزدهم با عنوان
«تحلیل بقاء»، ابتدا روشهای توصیفی مربوطه، روش کاپلان مایر و تحلیل جدول عمر یا Life Table نیز توضیح داده شد. پس از آن، روش تحلیل تک متغیره یا مقایسه منحنیهای بقاء با روش Log Rank نیز توضیح داده شده و در ادامه شاخص مخاطره نسبی یا Hazard Ratio مورد تشریح قرار میگیرد. پس از این مطالب، روش رگرسیونی مخصوص داده های بقاء یا همان روش Cox Regression مورد اشاره قرار میگیرد.
در
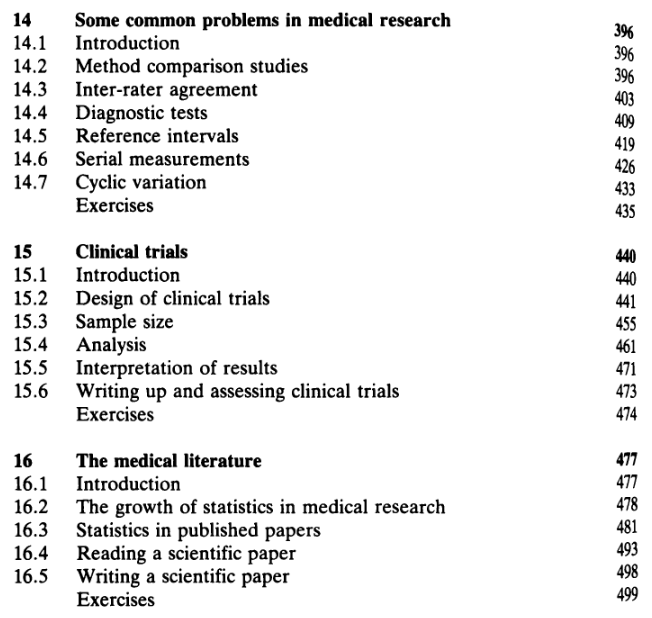
فصل چهاردهم با عنوان
«برخی مسائل شایع در پژوهشهای پزشکی»، مجدداً پروفسور آلتمن به سراغ علایق خود که در واقع منطبق بر مشکلات رایج در مطالعات پژوهشی سلامت و پزشکی بوده، میرود و به تشریح برخی موضوعات و مبانی کاربردی در سنجش یا اندازه گیریها، یعنی روایی، پایایی، تکرار پذیری، توافق بین سنجشها یا اندازه گیریها در مطالعات پژوهشی و ...، میپردازد. شاخصهای کاپای ساده و کاپای وزنی، بعنوان شاخصهای توافق مورد توجه این فصل قرار میگیرد. در ادامه، موضوع مهم تستهای تشخیصی و مطالعات پژوهشی ارزش تشخیصی و همچنین شاخصهای مهم این مطالعات، یعنی حساسیت، ویژگی، ارزش اخباری مثبت و منفی و تاثیرات شیوع پیامد یا بیماری بر روی برخی شاخصها (ارزش اخباری مثبت و منفی)، اشاره مینماید. ضمناً شاخصهای نسبت درستنمایی مثبت و منفی و کاربردهای آنها نیز مورد توجه قرار میگیرد.
در ادامه این فصل، موضوع مهم مطالعات مقادیر مرجع یا Reference Values تشریح میشود. انتخاب نمونه از جامعه هدف تست مورد نظر و محاسبات تست مرجع و شاخصهای مرکزی و پراکندگی مربوطه نیز مورد توجه مولف قرار گرفته، همچنین رابطه برخی متغیرهای دموگرافیک مانند سن و جنس با مقادیر مرجع، نیز تشریح گردیده است. در ادامه این موضوعات مهم در مقادیر مرجع تستهای مختلف، برخی ملاحظات مهم در سنجشهای سریال (پشت سر هم) و ملاحظات مختلف مرتبط با تغییرات سیکلیک در برخی تستها (مانند هورمونها و ...) و همچنین شیوه ارائه گزارش گرافیکی از این تستها و متدولوژیهای مربوطه، مورد توجه قرار میگیرد.
 فصل پانزدهم
فصل پانزدهم با عنوان
«کارآزماییهای بالینی»، بطور اختصاصی به اصول طراحی و اجرای انواع کارآزماییهای بالینی و فعالیتهای زیرمجموعه آنها، اجزاء مرتبط با مطلوبیت طراحی در این مطالعات، مانند تخصیص تصادفی و انواع آن، کورسازی گروههای تحت مطالعه و ... پرداخته و سپس به انواع طراحیهای رایج این مطالعات میپردازد. در این فصل، یک بخش نسبتاً مجزا در مورد محاسبه حجم نمونه کارآزماییهای بالینی وجود دارد که مبنای آن نوموگرام متعلق به خود مولف (نوموگرام آلتمن) است که در سال 1982 تدوین گردیده بود. در بخش بعدی این فصل با عنوان تحلیل آماری کارآزماییهای بالینی، اصول تجزیه و تحلیل آماری این مطالعات و برخی مشکلات یا نگرانیهای تحلیلی در این مطالعات مانند طراحیهای دارای سنجشهای تکراری قبل و بعد، تحلیل زیرگروهها، انحراف از پروتکول کارآزمایی و کارآزماییهای متقاطع، مورد توجه مولف قرار گرفته است.
فصل شانزدهم با عنوان
«متون یا منابع پزشکی» به موضوع مهم نقش و جایگاه آمار در نگارش مقالات منتشره در ژورنالهای پزشکی میپردازد. یک طبقه بندی بسیار کاربردی توسط مولف صورت میگیرد که خطاهای موجود در مقالات را به 5 دسته خطا در طراحی، اجراء، آنالیز آماری، ارائه نتایج و تفسیر، تقسیم بندی مینماید. در انتهای این فصل نیز یک چک لیست بسیار کاربردی برای خواندن یک مقاله پیشنهاد مینماید.
در پایان این مقاله مروری که هدف آن ارزیابی محتوای کتاب ارزشمند پروفسور آلتمن با عنوان «آمار کاربردی برای پژوهشهای پزشکی» بود، ضمن مروری بر جایگاه این کتاب و همچنین جایگاه مولف آن در بین متخصصین آمار زیستی، بصورت گذرا بر محتوای 16 فصل بسیار مهم این کتاب، تاملی داشتیم. این کتاب یکی از کاربردی ترین کتب آماری در مجموع کتب آماری و بخصوص در بین کتب آمار زیستی یا پزشکی، خواهد بود. مطالعه این کتاب را به همه علاقمندان، متخصصین، اعضای هیات علمی گروه سلامت و پزشکی، دانشجویان تحصیلات تکمیلی و در مجموع کلیه افرادیکه میخواهند درک بالاتری از مفهوم آمار در مقالات و متون علمی و پژوهشی داشته باشند، توصیه مینمایم.
ضمناً همانطور که در بخش اول این مقاله اشاره داشتم، سطح این کتاب ارزشمند، علی رغم سطح بالای مطالب و محتوای آن، منطبق بر سطوح مقدماتی درس آمار برای گروههای پزشکی و سلامت میباشد، هر چند مطالب برخی فصول این کتاب، از سطح مقدامتی بالاتر بوده و به سطوح پیشرفته، تمایل بیشتری دارد.
دکتر عباس کشتکار، جمعه 12 خرداد 1396



.png)
.png)
.png)
.png)
.png)